問題背景
搜索關鍵字智能提示是一個搜索應用的標配,主要作用是避免用戶輸入錯誤的搜索詞,并將用戶引導到相應的關鍵詞上,以提升用戶搜索體驗。
美團CRM系統中存在數以百萬計的商家,為了讓用戶快速查找到目標商家,我們基于solrcloud實現了商家搜索模塊。用戶在查找商家時主要輸入商戶名、商戶地址進行搜索,為了提升用戶的搜索體驗和輸入效率,本文實現了一種基于solr前綴匹配查詢關鍵字智能提示(Suggestion)實現。
需求分析
1.支持前綴匹配原則
在搜索框中輸入“海底”,搜索框下面會以海底為前綴,展示“海底撈”、“海底撈火鍋”、“海底世界”等等搜索詞;輸入“萬達”,會提示“萬達影城”、“萬達廣場”、“萬達百貨”等搜索詞。
2.同時支持漢字、拼音輸入
由于中文的特點,如果搜索自動提示可以支持拼音的話會給用戶帶來更大的方便,免得切換輸入法。比如,輸入“haidi”提示的關鍵字和輸入“海底”提示的一樣,輸入“wanda”與輸入“萬達”提示的關鍵字一樣。
3.支持多音字輸入提示
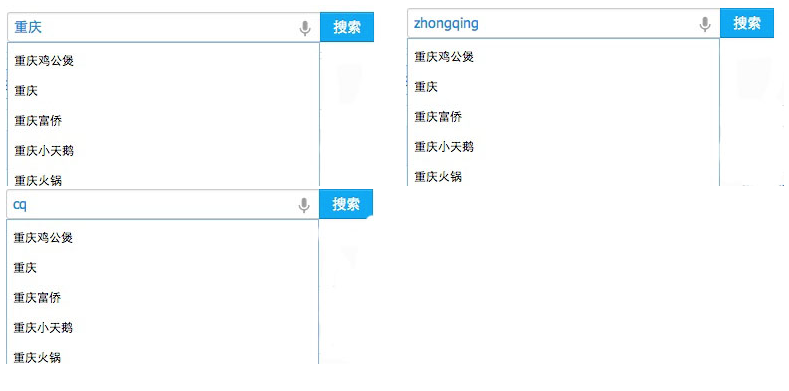
比如輸入“chongqing”或者“zhongqing”都能提示出“重慶火鍋”、“重慶烤魚”、“重慶小天鵝”。
4.支持拼音縮寫輸入
對于較長關鍵字,為了提高輸入效率,有必要提供拼音縮寫輸入。比如輸入“hd”應該能提示出“haidi”相似的關鍵字,輸入“wd”也一樣能提示出“萬達”關鍵字。
基于用戶的歷史搜索行為,按照關鍵字熱度進行排序
為了提供suggest關鍵字的準確度,最終查詢結果,根據用戶查詢關鍵字的頻率進行排序,如輸入[重慶,chongqing,cq,zhongqing,zq] —> [“重慶火鍋”(f1),“重慶烤魚”(f2),“重慶小天鵝”(f3),…],查詢頻率f1 > f2 > f3。
解決方案
1.關鍵字收集
當用戶輸入一個前綴時,碰到提示的候選詞很多的時候,如何取舍,哪些展示在前面,哪些展示在后面?這就是一個搜索熱度的問題。用戶在使用搜索引擎查找商家時,會輸入大量的關鍵字,每一次輸入就是對關鍵字的一次投票,那么關鍵字被輸入的次數越多,它對應的查詢就比較熱門,所以需要把查詢的關鍵字記錄下來,并且統計出每個關鍵字的頻率,方便提示結果按照頻率排序。搜索引擎會通過日志文件把用戶每次檢索使用的所有檢索串都記錄下來,每個查詢串的長度為1-255字節。
2.漢字轉拼音
用戶輸入的關鍵字可能是漢字、數字,英文,拼音,特殊字符等等,由于需要實現拼音提示,我們需要把漢字轉換成拼音,java中考慮使用pinyin4j組件實現轉換。
3.拼音縮寫提取
考慮到需要支持拼音縮寫,漢字轉換拼音的過程中,順便提取出拼音縮寫,如“chongqing”,"zhongqing"--->"cq",”zq”。
4.多音字全排列
要支持多音字提示,對查詢串轉換成拼音后,需要實現一個全排列組合,字符串多音字全排列算法如下:
Java Code復制內容到剪貼板
- public static List getPermutationSentence(List> termArrays,int start) {
-
- if (CollectionUtils.isEmpty(termArrays))
- return Collections.emptyList();
-
- int size = termArrays.size();
- if (start 0 || start >= size) {
- return Collections.emptyList();
- }
-
- if (start == size-1) {
- return termArrays.get(start);
- }
-
- ListString> strings = termArrays.get(start);
-
- ListString> permutationSentences = getPermutationSentence(termArrays, start + 1);
-
- if (CollectionUtils.isEmpty(strings)) {
- return permutationSentences;
- }
-
- if (CollectionUtils.isEmpty(permutationSentences)) {
- return strings;
- }
-
- ListString> result = new ArrayListString>();
- for (String pre : strings) {
- for (String suffix : permutationSentences) {
- result.add(pre+suffix);
- }
- }
-
- return result;
- }
索引與前綴查詢
方案一 Trie樹 + TopK算法
Trie樹即字典樹,又稱單詞查找樹或鍵樹,是一種樹形結構,是一種哈希樹的變種。典型應用是用于統計和排序大量的字符串(但不僅限于字符串),所以經常被搜索引擎系統用于文本詞頻統計。它的優點是:最大限度地減少無謂的字符串比較,查詢效率比哈希表高。Trie是一顆存儲多個字符串的樹。相鄰節點間的邊代表一個字符,這樣樹的每條分支代表一則子串,而樹的葉節點則代表完整的字符串。和普通樹不同的地方是,相同的字符串前綴共享同一條分支。例如,給出一組單詞inn, int, at, age, adv, ant, 我們可以得到下面的Trie:

從上圖可知,當用戶輸入前綴i的時候,搜索框可能會展示以i為前綴的“in”,“inn”,”int"等關鍵詞,再當用戶輸入前綴a的時候,搜索框里面可能會提示以a為前綴的“ate”等關鍵詞。如此,實現搜索引擎智能提示suggestion的第一個步驟便清晰了,即用trie樹存儲大量字符串,當前綴固定時,存儲相對來說比較熱的后綴。
TopK算法用于解決統計熱詞的問題。解決TopK問題主要有兩種策略:hashMap統計+排序、堆排序
hashmap統計: 先對這批海量數據預處理。具體方法是:維護一個Key為Query字串,Value為該Query出現次數的HashTable,即hash_map(Query,Value),每次讀取一個Query,如果該字串不在Table中,那么加入該字串,并且將Value值設為1;如果該字串在Table中,那么將該字串的計數加一即可,最終在O(N)的時間復雜度內用Hash表完成了統計。
堆排序:借助堆這個數據結構,找出Top K,時間復雜度為N‘logK。即借助堆結構,我們可以在log量級的時間內查找和調整/移動。因此,維護一個K(該題目中是10)大小的小根堆,然后遍歷300萬的Query,分別和根元素進行對比。所以,我們最終的時間復雜度是:O(N) + N' * O(logK),(N為1000萬,N’為300萬)。
該方案存在的問題是:
建索引和查詢的時候都要把漢字轉換成拼音,查詢完成后還得把拼音轉換成漢字顯示,且需要考慮數字和特殊字符。
需要維護拼音、縮寫兩棵Trie樹。
方案二 Solr自帶Suggest智能提示
Solr作為一個應用廣泛的搜索引擎系統,它內置了智能提示功能,叫做Suggest模塊。該模塊可選擇基于提示詞文本做智能提示,還支持通過針對索引的某個字段建立索引詞庫做智能提示。 (詳見solr的wiki頁面http://wiki.apache.org/solr/Suggester)
該方案存在的問題是:
返回的結果是基于索引中字段的詞頻進行排序,不是用戶搜索關鍵字的頻率,因此不能將一些熱門關鍵字排在前面。
拼音提示,多音字,縮寫還是要另外加索引字段。
方案三 Solrcloud建立單獨的collection,利用solr前綴查詢實現
如前所述,以上兩個方案在實施起來都存在一些問題,Trie樹+TopK算法,在處理漢字suggest時不是很優雅,且需要維護兩棵Trie樹,實施起來比較復雜;Solr自帶的suggest智能提示組件存在問題是使用freq排序算法,返回的結果完全基于索引中字符的出現次數,沒有兼顧用戶搜索詞語的頻率,因此無法將一些熱門詞排在更靠前的位置。于是,我們繼續尋找一種解決這個問題更加優雅的方案。
至此,我們考慮專門為關鍵字建立一個索引collection,利用solr前綴查詢實現。solr中的copyField能很好解決我們同時索引多個字段(漢字、pinyin, abbre)的需求,且field的multiValued屬性設置為true時能解決同一個關鍵字的多音字組合問題。配置如下:
schema.xml:
XML/HTML Code復制內容到剪貼板
- field name="kw" type="string" indexed="true" stored="true" />
- field name="pinyin" type="string" indexed="true" stored="false" multiValued="true"/>
- field name="abbre" type="string" indexed="true" stored="false" multiValued="true"/>
- field name="kwfreq" type="int" indexed="true" stored="true" />
- field name="_version_" type="long" indexed="true" stored="true"/>
- field name="suggest" type="suggest_text" indexed="true" stored="false" multiValued="true" />
------------------multiValued表示字段是多值的-------------------------------------
XML/HTML Code復制內容到剪貼板
- uniqueKey>kw/uniqueKey>
- defaultSearchField>suggest/defaultSearchField>
說明:
kw為原始關鍵字
pinyin和abbre的multiValued=true,在使用solrj建此索引時,定義成集合類型即可:如關鍵字“重慶”的pinyin字段為{chongqing,zhongqing}, abbre字段為{cq, zq}
kwfreq為用戶搜索關鍵的頻率,用于查詢的時候排序
-------------------------------------------------------
XML/HTML Code復制內容到剪貼板
- copyField source="kw" dest="suggest" />
- copyField source="pinyin" dest="suggest" />
- copyField source="abbre" dest="suggest" />
------------------suggest_text----------------------------------
XML/HTML Code復制內容到剪貼板
- fieldType name="suggest_text" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true">
- analyzer type="index">
- tokenizer class="solr.KeywordTokenizerFactory" />
- filter class="solr.SynonymFilterFactory"
- synonyms="synonyms.txt"
- ignoreCase="true"
- expand="true" />
- filter class="solr.StopFilterFactory"
- ignoreCase="true"
- words="stopwords.txt"
- enablePositionIncrements="true" />
- filter class="solr.LowerCaseFilterFactory" />
- filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt" />
- /analyzer>
- analyzer type="query">
- tokenizer class="solr.KeywordTokenizerFactory" />
- filter class="solr.StopFilterFactory"
- ignoreCase="true"
- words="stopwords.txt"
- enablePositionIncrements="true" />
- filter class="solr.LowerCaseFilterFactory" />
- filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt" />
- /analyzer>
- /fieldType>
KeywordTokenizerFactory:這個分詞器不進行任何分詞!整個字符流變為單個詞元。String域類型也有類似的效果,但是它不能配置文本分析的其它處理組件,比如大小寫轉換。任何用于排序和大部分Faceting功能的索引域,這個索引域只有能一個原始域值中的一個詞元。
前綴查詢構造:
Java Code復制內容到剪貼板
- private SolrQuery getSuggestQuery(String prefix, Integer limit) {
- SolrQuery solrQuery = new SolrQuery();
- StringBuilder sb = new StringBuilder();
- sb.append(“suggest:").append(prefix).append("*");
- solrQuery.setQuery(sb.toString());
- solrQuery.addField("kw");
- solrQuery.addField("kwfreq");
- solrQuery.addSort("kwfreq", SolrQuery.ORDER.desc);
- solrQuery.setStart(0);
- solrQuery.setRows(limit);
- return solrQuery;
- }
效果如下圖所示: