在MySQL中,新建立一張表,該表有三個字段,分別是id,a,b,插入1000條每個字段都相等的記錄,如下:
mysql> show create table t1\G
*************************** 1. row ***************************
Table: t1
Create Table: CREATE TABLE `t1` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `a` (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
mysql> select * from t1 limit 10;
+----+------+------+
| id | a | b |
+----+------+------+
| 1 | 1 | 1 |
| 2 | 2 | 2 |
| 3 | 3 | 3 |
| 4 | 4 | 4 |
| 5 | 5 | 5 |
| 6 | 6 | 6 |
| 7 | 7 | 7 |
| 8 | 8 | 8 |
| 9 | 9 | 9 |
| 10 | 10 | 10 |
+----+------+------+
10 rows in set (0.00 sec)
當我們執行下面包含group by的SQL時,查看執行計劃,可以看到:
mysql> explain select id%10 as m, count(*) as c from t1 group by m limit 10;
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------------------+
| 1 | SIMPLE | t1 | NULL | index | PRIMARY,a | a | 5 | NULL | 1000 | 100.00 | Using index; Using temporary; Using filesort |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------------------+
1 row in set, 1 warning (0.00 sec)
最后面有:
- using index:覆蓋索引
- using temporary:使用了內存臨時表
- using filesort:使用了排序操作
為了更好的理解這個group by語句的執行過程,我畫一個圖來表示:
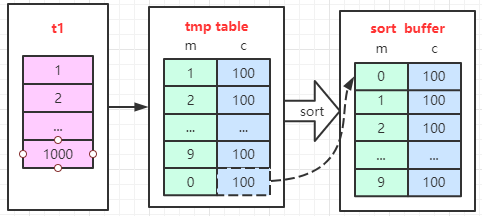
對照上面這個表,我們不難發現,這個group by的語句執行流程是下面這樣的:
a、首先創建內存臨時表,內存表里有兩個字段m和c,主鍵是m;m是id%10,而c是統計的count(*) 個數
b、掃描表t1的索引a,依次取出葉子節點上的id值,計算id%10的結果,記為x;此時如果臨時表中沒有主鍵為x的行,就插入一個記錄(x,1);如果表中有主鍵為x的行,就將x這一行的c值加1;
c、遍歷完成后,再根據字段m做排序,得到結果集返回給客戶端。(注意,這個排序的動作是group by自動添加的。)
如果我們不想讓group by語句幫我們自動排序,可以添加上order by null在語句的末尾,這樣就可以去掉order by之后的排序過程了。如下:
mysql> explain select id%10 as m, count(*) as c from t1 group by m order by null;
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+------------------------------+
| 1 | SIMPLE | t1 | NULL | index | PRIMARY,a | a | 5 | NULL | 1000 | 100.00 | Using index; Using temporary |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+------------------------------+
1 row in set, 1 warning (0.00 sec)
可以看到,explain最后面的using filesort字樣已經不見了。再來看下結果:
mysql> select id%10 as m, count(*) as c from t1 group by m;
+------+-----+
| m | c |
+------+-----+
| 0 | 100 |
| 1 | 100 |
| 2 | 100 |
| 3 | 100 |
| 4 | 100 |
| 5 | 100 |
| 6 | 100 |
| 7 | 100 |
| 8 | 100 |
| 9 | 100 |
+------+-----+
10 rows in set (0.00 sec)
mysql> select id%10 as m, count(*) as c from t1 group by m order by null;
+------+-----+
| m | c |
+------+-----+
| 1 | 100 |
| 2 | 100 |
| 3 | 100 |
| 4 | 100 |
| 5 | 100 |
| 6 | 100 |
| 7 | 100 |
| 8 | 100 |
| 9 | 100 |
| 0 | 100 |
+------+-----+
10 rows in set (0.00 sec)
當我們不加order by null的時候,group by會自動為我們進行排序,所以m=0的記錄會在第一條的位置,如果我們加上order by null,那么group by就不會自動排序,那么m=0的記錄就在最后面了。
我們當前這個語句,表t1中一共有1000條記錄,對10取余,只有10個結果,在內存臨時表中還可以放下,內存臨時表在MySQL中,通過tmp_table_size來控制。
mysql> show variables like "%tmp_table%";
+----------------+----------+
| Variable_name | Value |
+----------------+----------+
| max_tmp_tables | 32 |
| tmp_table_size | 39845888 |
+----------------+----------+
2 rows in set, 1 warning (0.00 sec)
當我們的結果足夠大,而內存臨時表不足以保存的時候,MySQL就會使用磁盤臨時表,整個訪問的速度就變得很慢了。那么針對group by操作,我們如何優化?
01
group by優化之索引
從上面的描述中不難看出,group by進行分組的時候,創建的臨時表都是帶一個唯一索引的。如果數據量很大,group by的執行速度就會很慢,要想優化這種情況,還得分析為什么group by 需要臨時表?
這個問題其實是因為group by的邏輯是統計不同的值出現的次數,由于每一行記錄做group by之后的結果都是無序的,所以就需要一個臨時表存儲這些中間結果集。如果我們的所有值都是排列好的,有序的,那情況會怎樣呢?
例如,我們有個表的記錄id列是:
0,0,0,1,1,2,2,2,2,3,4,4,
當我們使用group by的時候,就直接從左到右,累計相同的值即可。這樣就不需要臨時表了。
上面的結構我們也不陌生,當我們以在某個數據列上創建索引的時候,這個列本身就是排序的,當group by是以這個列為條件的時候,那么這個過程就不需要排序,因為索引是自然排序的。為了實現這個優化,我們給表t1新增一個列z,如下:
mysql> alter table t1 add column z int generated always as(id % 10), add index(z);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> select z as m, count(*) as c from t1 group by z;
+------+-----+
| m | c |
+------+-----+
| 0 | 100 |
| 1 | 100 |
| 2 | 100 |
| 3 | 100 |
| 4 | 100 |
| 5 | 100 |
| 6 | 100 |
| 7 | 100 |
| 8 | 100 |
| 9 | 100 |
+------+-----+
10 rows in set (0.00 sec)
mysql> explain select z as m, count(*) as c from t1 group by z;
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t1 | NULL | index | z | z | 5 | NULL | 1000 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
我們新增字段z,z的值是id%10之后的值,并且創建索引,再通過group by對這個z列進行分組,可以看到,結果中已經沒有臨時表了。
所以,使用索引可以幫助我們去掉group by依賴的臨時表
02
group by優化---直接排序
如果我們已經知道表的數據量特別大,內存臨時表肯定不足以容納排序的時候,其實我們可以通過告知group by進行磁盤排序,而直接跳過內存臨時表的排序過程。
其實在MySQL中是有這樣的方法的:在group by語句中加入SQL_BIG_RESULT這個提示(hint),就可以告訴優化器:這個語句涉及的數據量很大,請直接用磁盤臨時表。當我們使用這個語句的時候,MySQL將自動利用數組的方法來組織磁盤臨時表中的字段,而不是我們所周知的B+樹。關于這個知識點,這里給出官方文檔的介紹:
SQL_BIG_RESULT or SQL_SMALL_RESULT can be used with GROUP BY or DISTINCT to tell the optimizer that the result set has many rows or is small, respectively. For SQL_BIG_RESULT, MySQL directly uses disk-based temporary tables if they are created, and prefers sorting to using a temporary table with a key on the GROUP BY elements. For SQL_SMALL_RESULT, MySQL uses in-memory temporary tables to store the resulting table instead of using sorting. This should not normally be needed.
整個group by的處理過程將會變成:
a、初始化sort_buffer,確定放入一個整型字段,記為m;
b、掃描表t1的索引a,依次取出里面的id值, 將 id%100的值存入sort_buffer中;
c、掃描完成后,對sort_buffer的字段m做排序(如果sort_buffer內存不夠用,就會利用磁盤臨時文件輔助排序);
d、排序完成后,就得到了一個有序數組。類似0,0,0,1,1,2,2,3,3,3,4,4,4,4這樣
e、根據有序數組,得到數組里面的不同值,以及每個值的出現次數。
昨天的文章中我們分析了union 語句會使用臨時表,今天的內容我們分析了group by語句使用臨時表的情況,那么MySQL究竟什么時候會使用臨時表呢?
MySQL什么時候會使用內部臨時表?
1、如果語句執行過程可以一邊讀數據,一邊直接得到結果,是不需要額外內存的,否則就需要額外的內存,來保存中間結果;
2、如果執行邏輯需要用到二維表特性,就會優先考慮使用臨時表。比如union需要用到唯一索引約束, group by還需要用到另外一個字段來存累積計數。
以上就是MySQL group by語句如何優化的詳細內容,更多關于MySQL group by優化的資料請關注腳本之家其它相關文章!
您可能感興趣的文章:- MySQL優化GROUP BY(松散索引掃描與緊湊索引掃描)
- MySQL優化GROUP BY方案
- MySQL Group by的優化詳解
