目錄
- 一、bs4解析
- 二、xpath解析
- 三、xpath解析(二值化處理后展示圖片)
- 四、分析過程
一、bs4解析
import requests
from bs4 import BeautifulSoup
import datetime
if __name__=='__main__':
url = 'https://www.bilibili.com/v/popular/rank/all'
headers = {
//設置自己瀏覽器的請求頭
}
page_text=requests.get(url=url,headers=headers).text
soup=BeautifulSoup(page_text,'lxml')
li_list=soup.select('.rank-list > li')
with open('bZhanRank_bs4.txt','w',encoding='utf-8') as fp:
fp.write('當前爬取熱榜的時間為:'+str(datetime.datetime.now())+'\n\n')
for li in li_list:
#解析視頻排行
li_rank=li.find('div',class_='num').string
li_rank='視頻排行為:'+li_rank+','
#解析視頻標題
li_title=li.find('div',class_='info').a.string.strip()
li_title='視頻標題為:'+li_title+','
#解析視頻播放量
li_viewCount=li.select('.detail>span')[0].text.strip()
li_viewCount='視頻播放量為:'+li_viewCount+', '
#解析彈幕數量
li_danmuCount = li.select('.detail>span')[1].text.strip()
li_danmuCount='視頻彈幕數量為:'+li_danmuCount+', '
#解析視頻作者
li_upName=li.find('span',class_='data-box up-name').text.strip()
li_upName='視頻up主:'+li_upName+', '
#解析綜合評分
li_zongheScore=li.find('div',class_='pts').div.string
li_zongheScore='視頻綜合得分為:'+li_zongheScore
fp.write(li_rank+li_title+li_viewCount+li_danmuCount+li_upName+li_zongheScore+'\n')
爬取結果如下:

二、xpath解析
import requests
from lxml import etree
import datetime
if __name__ == "__main__":
#設置請求頭
headers = {
//設置自己瀏覽器的請求頭
}
#設置url
url = 'https://www.bilibili.com/v/popular/rank/all'
#爬取主頁面的源碼文件
page_text = requests.get(url=url,headers=headers).content.decode('utf-8')
#使用etree對象進行實例化
tree = etree.HTML(page_text)
#爬取各視頻的標簽所在位置
li_list = tree.xpath('//ul[@class="rank-list"]/li')
#對爬取到的內容進行存儲
with open('./bZhanRank.txt', 'w', encoding='utf-8') as fp:
#記錄爬取數據的時間
fp.write('時間:'+str(datetime.datetime.now())+'\n\n')
# 使用循環結構,提取各標簽中的所需信息
for li in li_list:
#讀取視頻排名
li_rank=li.xpath('.//div[@class="num"]/text()')
#[0]使用索引從列表中拿出字符串
li_rank='視頻排行:'+li_rank[0]+'\n'
#讀取視頻標題
li_title = li.xpath('.//a/text()')
li_title='視頻標題:'+li_title[0]+'\n'
#讀取視頻播放量
li_viewCount=li.xpath('.//div[@class="detail"]/span[1]/text()')
#.strip()去掉字符串中多余的空格
li_viewCount='視頻播放量:'+li_viewCount[0].strip()+'\n'
#讀取視頻彈幕數量
li_barrageCount = li.xpath('.//div[@class="detail"]/span[2]/text()')
li_barrageCount='視頻彈幕數量:'+li_barrageCount[0].strip()+'\n'
#讀取視頻up主昵稱
li_upName=li.xpath('.//span[@class="data-box up-name"]//text()')
li_upName='視頻up主:'+li_upName[0].strip()+'\n'
#讀取視頻的綜合評分
li_score=li.xpath('.//div[@class="pts"]/div/text()')
li_score='視頻綜合評分:'+li_score[0]+'\n\n'
#存儲文件
fp.write(li_rank+li_title+li_viewCount+li_barrageCount+li_upName+li_score)
print(li_rank+'爬取成功!!!!')
爬取結果如下:

三、xpath解析(二值化處理后展示圖片)
#----------第三方庫導入----------
import requests#爬取網頁源代碼
from lxml import etree#使用xpath進行數據解析
import datetime#添加爬取數據的時刻
from PIL import Image#用于打開和重加載圖片
from cv2 import cv2#對圖片進行二值化處理
from io import BytesIO#對圖片進行格式轉換
import re#對源代碼進行正則處理
#----------函數----------
def dJpg(url,title):
"""
輸入url 然后對b站webp格式的圖片 進行格式轉換為jpeg后 進行保存
:param url:(url)
:return:(null+保存圖片文件)
"""
headers = {
//設置自己瀏覽器的請求頭
}
resp = requests.get(url, headers=headers)
byte_stream = BytesIO(resp.content)
im = Image.open(byte_stream)
if im.mode == "RGBA":
im.load()
background = Image.new("RGB", im.size, (255, 255, 255))
background.paste(im, mask=im.split()[3])
im.save(title+'.jpg', 'JPEG')
def handle_image(img_path):
"""
對RGB三通道圖片進行二值化處理
:param img_path:(圖片路徑)
:return:(返回處理后的圖片)
"""
# 讀取圖片
img = cv2.imread(img_path)
# 將圖片轉化成灰度圖
gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
# 將灰度圖轉化成二值圖,像素值超過127的都會被重新賦值成255
ret, binary = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
return binary
#----------程序主入口----------
if __name__ == "__main__":
#-----變量存放-----
list_rank = [] # 存放視頻標題的列表
list_pic_url = [] # 存放圖片網址的列表
#-----數據解析(除圖片外)-----
#設置請求頭
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.2261 SLBChan/10'
}
#設置url
url = 'https://www.bilibili.com/v/popular/rank/all'
#爬取主頁面的源碼文件
page_text = requests.get(url=url,headers=headers).content.decode('utf-8')
#使用etree對象進行實例化
tree = etree.HTML(page_text)
#爬取各視頻的標簽所在位置
li_list = tree.xpath('//ul[@class="rank-list"]/li')
#-----數據解析(圖片)-----
# 由于無法對圖片的網址進行標簽定位,現對源代碼進行正則處理
others_ex = r'"others".*?"tid"(.*?)]'
list_others = re.findall(others_ex, page_text, re.S)
# 使用循環替換掉源代碼中others部分
for l in list_others:
page_text = page_text.replace(l, '')
pic_ex = r'"copyright":.*?,"pic":"(.*?)","title":".*?"'
list_pic = re.findall(pic_ex, page_text, re.S)
# 獲取圖片url組成部分的索引
index = list_pic[0].rfind('u002F')
#對爬取到的url關鍵字進行拼接組成一個完整的url
for i in list_pic:
pic_url = 'http://i1.hdslb.com/bfs/archive/' + i[index + 5:] + '@228w_140h_1c.webp'
list_pic_url.append(pic_url)
#-----數據保存-----
#對爬取到的內容進行存儲
with open('./bZhanRank2.txt', 'w', encoding='utf-8') as fp:
#記錄爬取數據的時間
fp.write('b站視頻排行榜,'+'時間:'+str(datetime.datetime.now())+'\n')
fp.write('作者:MB\n')
fp.write('*'*10+'以下為排行榜內容'+'*'*10+'\n\n')
# 使用循環結構,提取各標簽中的所需信息
for i in range(len(li_list)):
#讀取視頻排名
li_rank=li_list[i].xpath('.//div[@class="num"]/text()')
pic_title=li_rank#將不含中文的視頻排行作為圖片名稱進行賦值
#[0]使用索引從列表中拿出字符串
li_rank='視頻排行:'+li_rank[0]+'\n'
#讀取視頻標題
li_title =li_list[i].xpath('.//a/text()')
li_title='視頻標題:'+li_title[0]+'\n'
#讀取視頻播放量
li_viewCount=li_list[i].xpath('.//div[@class="detail"]/span[1]/text()')
#.strip()去掉字符串中多余的空格
li_viewCount='視頻播放量:'+li_viewCount[0].strip()+'\n'
#讀取視頻彈幕數量
li_barrageCount = li_list[i].xpath('.//div[@class="detail"]/span[2]/text()')
li_barrageCount='視頻彈幕數量:'+li_barrageCount[0].strip()+'\n'
#讀取視頻up主昵稱
li_upName=li_list[i].xpath('.//span[@class="data-box up-name"]//text()')
li_upName='視頻up主:'+li_upName[0].strip()+'\n'
#讀取視頻的綜合評分
li_score=li_list[i].xpath('.//div[@class="pts"]/div/text()')
li_score='視頻綜合評分:'+li_score[0]+'\n\n'
# 存儲視頻信息(除圖片外)
fp.write(li_rank + li_title + li_viewCount + li_barrageCount + li_upName + li_score)
#使用函數處理圖片的url并且保存為jpeg格式
dJpg(list_pic_url[i], str(pic_title))
#使用函數對jpeg格式的餓圖片進行二值化處理
img = handle_image(str(pic_title) + '.jpg')
# 強制設置圖片大小(為防止記事本的行列大小溢出)
img = cv2.resize(img, (120, 40))
height, width = img.shape
for row in range(0, height):
for col in range(0, width):
# 像素值為0即黑色,那么將字符‘1'寫入到txt文件
if img[row][col] == 0:
ch = '1'
fp.write(ch)
# 否則寫入空格
else:
fp.write(' ')
fp.write('*\n')
fp.write('\n\n\n')
print(li_rank + '爬取成功!!!!')
在記事本進行顯示結果之前需要對記事本的格式進行下列更改以獲得更好的視覺效果:

爬取結果如下:(圖片展示,是下載網頁中的的封面圖片(webp格式),首先對其進行格式轉換為jpg格式,然后對其進行二值化處理(對于像素值大于127的像素點直接賦值為0,對于像素值大于127的像素點直接賦值為1)。然后遍歷所有的像素點,對于像素值為0的像素點(即為黑色),寫入“1”,對于像素值為1的像素點(即為白色),寫入“空格”,實現簡單的圖片模擬顯示。)

水平線上和水平線下的圖片并非一個時間點進行爬取。

上述圖片為了均衡文字顯示與圖像顯示之間的關系,所以圖片大小強制設定為較小的尺寸,圖片顯示并不清晰。要讓圖片顯示清晰,可以不考慮文字顯現效果,將圖片的尺寸設置較大并且更改記事本中的字體大小(以防串行),可以進行圖片較為清晰的展示,如下圖所示。

四、分析過程
(1)獲取url——獲取b站視頻排行榜的網址

(2)獲取請求頭——(右擊—檢查),打開開發者工具,點擊Network,隨便選擇一個數據包,復制其中的請求頭即可


(3)網頁分析——點擊開發者工具左上角的抓手工具,選中頁面中視頻,發現每個不同的視頻都存放在不同的li標簽中

(4)網頁分析——選中頁面中視頻的標題,發現標題內容存放在一個a標簽的文本內容中,剩下的視頻信息尋找方式同上述。

(5)網頁分析——在查看到視頻播放量信息時,發現其存放在span標簽下,含有空格,在編寫代碼時,使用strip()方法進行去除空格
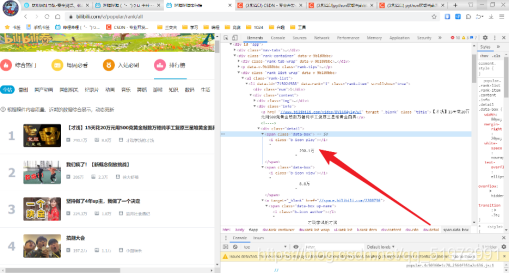
(6)調試代碼——調試代碼時,爬取的圖片url的列表為空

(7)排錯——檢查圖片url存放標簽位置,發現位置正確

(8)排錯——爬取信息為空,可能網頁為減輕加載負擔,使用的是JavaScript異步加載,在開發者工具中,點擊XHR,在數據包中尋找存放圖片url的數據包,發現并不存在
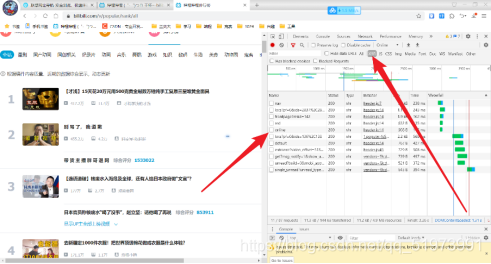
(9)排錯——(右鍵—查看網頁源代碼),在源代碼中搜索圖片的url,發現所有圖片的url全部存放在網頁源代碼的最后面,可以考慮使用正則表達式進行解析

(10)排錯——使用正則解析的過程中,返現others列表,此列表為部分視頻下方的視頻推薦,需進行刪除,否則影響正則表達式進行解析


到此這篇關于Python爬蟲之爬取嗶哩嗶哩熱門視頻排行榜的文章就介紹到這了,更多相關Python爬取B站排行榜內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- python爬蟲請求庫httpx和parsel解析庫的使用測評
- Python爬蟲之爬取最新更新的小說網站
- 用Python爬蟲破解滑動驗證碼的案例解析
- Python爬蟲爬取愛奇藝電影片庫首頁的實例代碼
- 上手簡單,功能強大的Python爬蟲框架——feapder
- python爬蟲之bs4數據解析
- python爬蟲之爬取百度翻譯
- python爬蟲基礎之簡易網頁搜集器
- python爬蟲之利用selenium模塊自動登錄CSDN
- python爬蟲之爬取筆趣閣小說
- python爬蟲之利用Selenium+Requests爬取拉勾網
- python基礎之爬蟲入門
